演示地址:模板1 https://www.94imm.com、 模板2 http://mm.luzi.gq/、 模板3 http://mm.94imm.com
git地址:https://git.coding.net/zxy_coding/94imm.git
一、单独部署
1.环境需求Python3.6、mysql5.7、nginx(可选)。系统版本推荐centos7 64位
2.环境搭建
python3.6安装,参考 https://www.dablog.cn/index.php/archives/9/
nginx安装,参考 https://www.dablog.cn/index.php/archives/10/
mysql5.7安装,参考 https://www.dablog.cn/index.php/archives/11/
安装程序依赖,进入程序目录,输入:pip3 install -r requirements.txt
如pip安装mysqlclient报错,参考 https://www.dablog.cn/index.php/archives/12/
3.程序安装
修改silumz下settings.py文件中数据库的配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'xxxx',
'USER': 'root',
'PASSWORD': 'xxxx',
'HOST': '127.0.0.1',
'PORT': '3306',
}}
创建相应数据库,导入程序目录下的sql文件
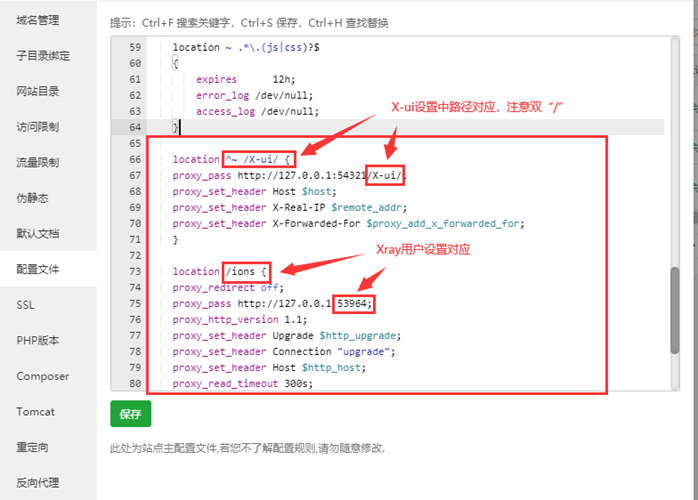
修改nginx配置文件(centos7 /etc/nginx/nginx.conf)
配置文件的server中的location字段如下修改
location / {
proxy_pass http://127.0.0.1:8000;
index index.html index.htm;
}重启nginx,访问网站即可
4.修改爬虫中的数据库地址
爬虫位于crawler目录下,每一个文件都是独立的,可单独执行
建议第一次运行时修改爬虫参数为采集全站,运行完修改参数为采集第一页,然后在linux中添加定时任务。实现自动采集
5.启动程序
进入程序目录,uwsgi --ini uwsgi.ini
6.模板修改
修改silumz下settings文件中的模板配置
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates'+"/"+"94imm")]94imm为模板名
模板文件位于templates文件夹下,修改相应页面
7.其他配置
将模板目录下的pagination.html文件放入python安装目录的/site-packages/dj_pagination/templates/pagination/下
(centos7 /usr/lib/python3.6/site-packages/dj_pagination/templates/pagination)
8.备注说明
其他系统请自行百度mysql python3.6.5 nginx的安装方法,程序安装方法相同
9.自动发布位于crawler下,执行python3 AutoPost.py 即可,注意输入文件夹时选择图片根目录,脚本会自动获取根目录下的所有子目录,并将子目录名作为标题,并复制子目录下所有文件到static/images/随机7个字母/ 下并删除源文件
10.压缩脚本位于crawler下,执行python3 Compress.py 即可,演示时使用兔玩的图片,发现图片太大,平均每张1M左右,600多套就占30G。所以写了个批量压缩脚本,同样是输入图片根目录,可以选在覆盖原图或在新目录压缩
二、配合宝塔部署
1.安装宝塔请查看宝塔官网:bt.cn
2.使用宝塔面板安装nginx、mysql、phpmyadmin(可选,需安装php)
3.添加站点,纯静态即可。

4.python3.6安装,参考 http://blog.51cto.com/wenguonideshou/2083301,软链地址有问题,注意看回复
5.python-dev安装,参考https://blog.csdn.net/default7/article/details/73368665
6.安装程序依赖,进入程序目录,输入:pip3 install -r requirements.txt
7.修改silumz下settings.py文件中数据库的配置(需使用宝塔创建数据库)
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'xxxx',
'USER': 'root',
'PASSWORD': 'xxxx',
'HOST': '127.0.0.1',
'PORT': '3306',
}}
创建相应数据库,导入程序目录下的sql文件
8.进入程序目录执行启动命令 uwsgi --ini uwsgi.ini
9.设置反向代理
设置刚才创建的网站,在反向代理中添加本地80端口:http://127.0.0.1:8000

爬虫使用说明及网站维护
1.爬虫位于crawler目录下,每一个文件都是独立的,可单独执行
建议第一次运行时修改爬虫参数为采集全站,运行完修改参数为采集第一页,然后在linux中添加定时任务。实现自动采集
①.单独安装时的自动采集:在root目录创建run.sh文件,写入如下内容
#!/bin/bash
cd ~/94imm/crawler &&
python3 crawler_mm131.py使用crontab -e 添加新的定时任务 /2 * /root/run.sh (每2小时采集一次)
②.配合宝塔面板设置自动采集:

2.模板修改
修改silumz下settings文件中的模板配置
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates'+"/"+"94imm")]94imm为模板名
模板文件位于templates文件夹下,修改相应页面
将模板目录下的pagination.html文件放入python安装目录的/site-packages/dj_pagination/templates/pagination/下
(centos7 /usr/lib/python3.6/site-packages/dj_pagination/templates/pagination)
3.模板为html文件,可在页面添加统计代码和广告代码
4.重启网站方法:
sh /程序目录/restart.sh
更新模板或完成采集后清空cache目录或重启网站才会生效
5.网友总结的使用经验:
https://sunsea.im/139/94imm_tips/
- 本地图片发布说明:cd 到 crawler,执行python3 AutoPost.py,根据提示输入本地图片所在路径,输入自动发布时间
图片压缩使用说明:有些网站可能未对图片进行压缩,一张图1m甚至几m不但降低传输速度还占空间。cd 到 crawler,执行
python3 Compress.py,
根据提示输入,默认10个线程压缩,如果服务器配置高可适当增加,只压缩图片质量,尺寸不变,实测1m图片压缩到100k后肉
眼看不出区别
更新功能:
1.删除图集:
cd 项目目录/crawler/
python3 delete_img.py
根据提示输入图集链接“/article/59885/”中的数字59885即可,同时删除数据库记录和采集的图片
2.下载采集未完成的图片
cd 项目目录/crawler/
python3 down_img.py
自动查找数据库中存在,但是static/images目录中不存在的记录,重新下载。并删除只有采集记录没有图片的数据
3.mm131、mmjpg爬虫修复
修复后的爬虫会在采集报错时跳过本条,下载报错时将图片再次放入下载队列,多次报错跳过图片,之前购买过爱美女、亿图的大佬私聊我qq更新下
4.采集数据共25g,5746个图集。包含mm131(去除后10页和质量差的),mmjpg前10页,爱美女全站,女神阁全站、亿图前10页
图片地址:https://image.moeclub.org/GoogleDrive/1VUOKRy9eYKSYpenz7QD4N3yN8g6aCNDQ
图片地址备用:https://mega.nz/#!fhNB2CoY!Eeo3Z3e9DsY0urs5Gk4nLz9usbttB4n2Rmfl2XG9M18
数据库sql文件:https://image.moeclub.org/GoogleDrive/1uKVoFQ1sQ7J89EaTkC2HY96A2w4brKSr
将采集数据放入项目static目录下,覆盖images目录。导入数据库sql文件